在现代办公中,文档格式的转换是一个常见而重要的需求。尤其是在将HTML文件转换为Word文档时,许多用户可能会面临各种挑战。本文将为大家详细介绍如何将HTML文件转换为Word文档,并提供一些实用的方法和工具。
首先,我们需要了解HTML和Word文档的基本特点。HTML(超文本标记语言)是一种用于创建网页的标记语言,通常被浏览器解析并显示内容。而Word文档(.doc或.docx)是由微软Office套件生成的文档,适合于文本处理和排版。因此,转换这两种格式需要考虑到格式兼容性和排版效果。
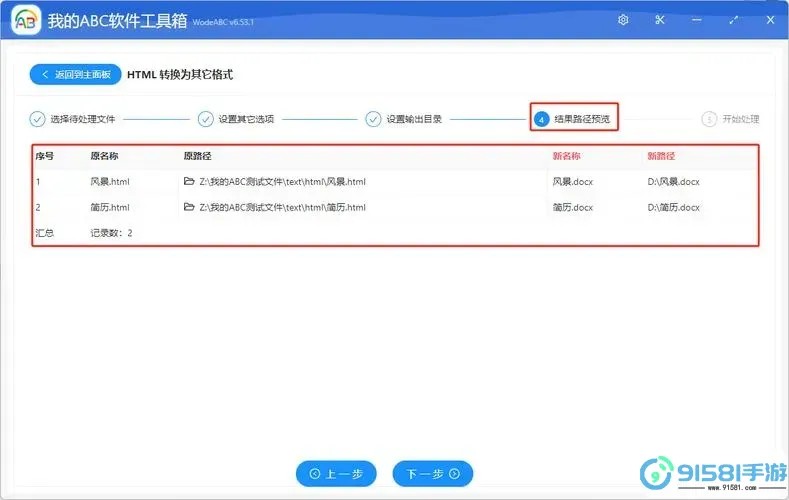
那么,如何将HTML文件转换为Word文档呢?有几种常见的方法可以实现这一目标:
方法一:使用在线转换工具
网络上有许多免费的在线转换工具,用户只需上传HTML文件,即可轻松下载生成的Word文档。例如,网站如“Online-Convert”和“Zamzar”等,都提供了这一功能。只需选择文件上传,选择目标格式为Word,点击转换即可。
方法二:使用Microsoft Word导入
如果你的电脑上已安装Microsoft Word,可以直接利用其导入功能。步骤如下:

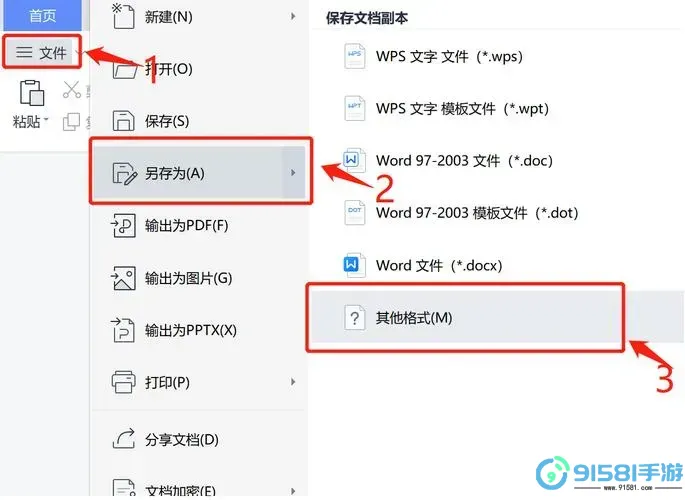
打开Microsoft Word软件。
在菜单中选择“文件”>“打开”,然后选择要转换的HTML文件。
Word会自动解析HTML文件并将其显示为文档。
完成后,点击“文件”>“另存为”,选择Word文档格式保存。
这种方法的好处是,可以保留HTML内容的格式和排版,且操作简单。
方法三:使用代码编写转换脚本
对于技术型用户,编写简单的Python脚本来实现HTML到Word的转换也是一个不错的选择。Python语言有丰富的第三方库,例如“BeautifulSoup”和“python-docx”,可以帮助用户进行格式化和文档生成。
以下是一个简单的代码示例:
import os from bs4 import BeautifulSoup from docx import Document # 读取HTML文件 with open(example.html, r, encoding=utf-8) as file: html_content = file.read() # 解析HTML soup = BeautifulSoup(html_content, html.parser) doc = Document() # 将读取的内容添加到Word文档中 for paragraph in soup.find_all(p): doc.add_paragraph(paragraph.get_text()) # 保存Word文档 doc.save(output.docx)以上代码读取HTML文件,解析其中的段落,并将其保存为Word文档。用户可以根据需要对代码进行修改和扩展。
方法四:使用转换软件
市面上还存在一些专门的文档转换软件,它们通常具有更多的功能和更好的兼容性。例如,“WPS Office”的转换工具,可以实现多种格式之间的转换,用户只需导入HTML文件,就能轻松转换为Word格式。
无论你选择哪一种方法,都应该注意以下几点:
确保HTML文件的结构清晰,避免片段缺失。
随时检查转换后的Word文档,及时调整格式。
对于包含复杂样式或多媒体内容的HTML文档,可能需要进行额外的手动调整。
综上所述,将HTML文件转换为Word文档的方法多种多样,用户可以根据自身需求和技术水平选择最适合的方式。不论是在工作中还是个人使用,掌握这一技能将大大提高文档处理的效率。




























